| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 오차역전파
- Branch
- computer vision
- Merge
- cv
- 분할정복
- Segment Anything
- 병리
- 그래프이론
- conflict
- forward
- 밑바닥부터 시작하는 딥러닝 1
- git commit
- Python
- 파이썬
- 그래프
- Backpropagation
- 알고리즘
- git add
- 딥러닝
- Git
- Heap
- Pathology
- 백준
- add
- DFS
- WSI
- BFS
- git branch
- git merge
- Today
- Total
나만의 길
Weakly supervised multiple instance learning histopathological tumor segmentation 리뷰 본문
Weakly supervised multiple instance learning histopathological tumor segmentation 리뷰
yunway 2024. 3. 15. 16:54https://arxiv.org/abs/2004.05024
Weakly supervised multiple instance learning histopathological tumor segmentation
Histopathological image segmentation is a challenging and important topic in medical imaging with tremendous potential impact in clinical practice. State of the art methods rely on hand-crafted annotations which hinder clinical translation since histology
arxiv.org
해당 논문은 MICCAI 2020에 기재된 논문으로 loss를 설계하는 approach 정도만 얻어가면 좋을 것 같습니다. 결과를 보니 성능적으로는 다소 아쉬운 느낌이 있어, method 부분만 참고하면 좋을 것 같습니다.
Abstract
- histopathological에서 image segmentation은 굉장히 중요하며, 어려운 task 중 하나임.
- 또 SOTA method는 대부분 수기로 만들어진 annotations에 의존하는데, 이는 암 조직들을 표현하는데 상당한 차이가 발생하여 실사용에 어려움이 있음.
본 논문에서는 이러한 문제 상황을 해결하기 위해, 대부분의 의료 시스템에서 이용 가능한 표준 annotation에 기반한 WSI segmentation을 위한 weakly supervised framework를 제시함. 또, multiple instance learning를 이용함.
Method
- WSI set : \(S = \{S_i\}\)
- Label : \(T_i = \{0, 1\}\)
- batch of Patches : \(\{p_s\}\)
목표는 binary anntation 만을 이용하여 segmentation or patch classifier를 만드는 것.
본래 fully SL은 patch level의 annotation이 필요함. 일반화 성능을 위해서는 patch가 수백 수천 장 이상이 필요한데, 이러한 방식으로 계속해서 annotation을 얻는 것은 실용적이지 않음.
따라서, 본 논문에서는 proxy patch-level ground truth labels을 만드는 것이 해당 framework의 주요 목표임.
proxy patch-level ground truth labels의 생성 과정은 다음과 같음.
- \( T_i = 0\) 이라면, 모든 patch의 label 0
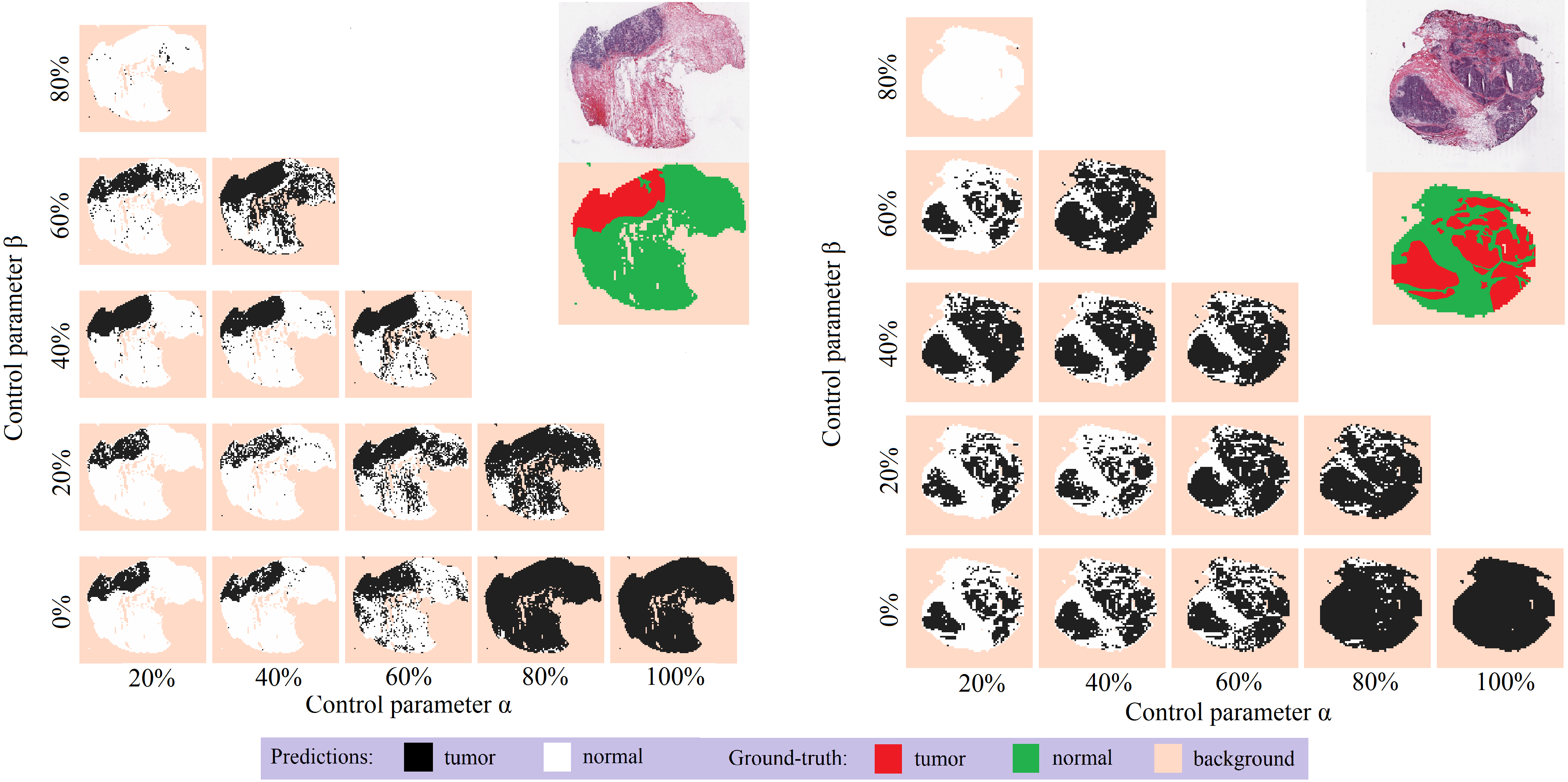
- \( T_i = 1\) 이라면, \(\alpha, \beta\) 2개의 하이퍼 파라미터를 사용하여 결정함
- 양성에 대해 최소 \(\alpha\)% 이상이면, label 1 할당
- 음성에 대해 최소 \(\beta\)% 이상이면, label 0 할당
- loss 계산 시, 위 조건을 만족하지 않는 patch는 버림.
\(\alpha\)는 양성 조직이 차지하는 최소한의 면적, \(\beta\)는 정상 조직이 차지하는 최소 하는 면적을 의미함.
여기서 중요한 부분은 \(\alpha, \beta\)의 합이 100% 넘어가면, 각각의 인스턴스에 대해 부과되는 100 - \((\alpha+ \beta)\)% > 0이 모순되고, 이는 proxy label을 생성하는데 문제가 될 수 있음.
따라서 하이퍼 파라미터 \(\alpha, \beta\)는 아래와 같이 범위를 정의함.
\(F = \{(\alpha, \beta);\alpha > 0, \beta \geq 0, \alpha+\beta \leq 1\}\)
최종적으로 proxy patch label을 생성하는 loss는 아래와 같음.

- \(P(f(p_s);p_{min},p_{max})\) : \(f(p_s)\)가 \(p_{min}\)과 \(p_{max}\)사이의 확률
- \(L(f(p_s), class)\) : 실제 class와 예측 class 간의 차이
- \(c_0, c_1\) : c0는 각 batch에 대한 평균치, 즉 1/N과 같음. c1은 class 불균형에 대한 가중치
- \(R_\alpha\) : WSI 당 recall 된 양성 patch의 비율 → 얼마나 많은 양성 영역을 정확하게 식별했는지
- \(R_\beta\) : WSI 당 recall된 음성 patch의 비율 → 얼마나 많은 정상 영역을 정확하게 식별했는지
해당 loss에서 empirical riskf를 최소화하기 위해 하나의 WSI당 충분한 양의 양성 patch를 recall 하도록 유도하지만 지나친 recall을 막기 위해(over recall) 정상 patch 비율(\(R_\beta\))를 조절함. 또 정상 WSI에서의 위양성 \((R_{FP})\)을 낮은 수준으로 유지함.
즉, 정상 WSI에서의 위양성을 줄이고 양성 WSI에서의 recall을 높이는 방식으로 loss를 설계
해당 loss의 장점은 NN을 포함하여 다양한 ML분야에서 학습될 수 있으며, 대부분의 loss와 결합할 수 있다는 점에서 장점이 있음. 또 생성된 확률을 이용하여 heatmap을 쉽게 생성할 수 있음.
Implementation details and Dataset
Framework setup & Architecture details
- 앞서 언급한 \(\alpha, \beta\)의 조합을 이용하여 set of parameter $F$ 형성
- \(\alpha, \beta\) 값은 0.2씩 증가시키며, 앞서 정의한 범위 내에서 조합은 총 21가지
- 이 중, \(\alpha\)는 0보다 커야 하므로(WSI가 양성인데 양성 비율이 0이면 모순이 발생함) 0을 제거하면 총 15가지 조합
- ResNet50을 backbone으로 사용, GAP 없이도 224x224로 13x13 output을 출력할 수 있음
- 224x224 크기의 patch 150개를 1 batch로 사용했으며, 20 배율로 sampling.

- 해당 그림은 편의상 10개를 표시했으나, 실제는 150개의 patch
- proxy vector를 생성하면, 각각을 proxy label과 결합함. 이때 label이 없는 patch는 버려짐
- 이를 BCE를 통해 loss를 계산하고, backpropagation 함.
- label이 없는 patch는 label이 생긴 주변 patch의 영향으로 계속해서 학습이 됨.
- V100 2대를 사용했고, 20 epoch을 진행했으며, 16시간 소요. benchmark 전체는 240시간
Dataset
TCGA WSI를 사용했고, 신장(2334개), 기관지(2168개), 유방(1979개)을 다뤘음. train 65%, validation 15%, test 20%로 구성. 본 논문에서는 test set을 In-distribution으로 명명함.
일반화 성능을 측정하기 위해 test에 대해서 각 병리학자가 신장(40장), 기관지(45장), 유방(45장)을 직접 annotation 했음.
앞서 train 과정에서 사용하지 않은 위치에서 추출한 WSI를 활용하여 일반화 성능을 추가적으로 평가함. 대장(35장), 난소(35장), 자궁체(30장)에서 추출한 WSI를 사용했고, 이는 pixel 단위의 annotation이며 Out-of-location으로 명명함. 오직 test에서만 사용.
또 PatchCamelyon dataset에서도 test를 진행함.
Result

- In-distribution에서 AUC는 0.675 ± 0.132이며, (α = 0.2, β = 0.2) 구성에서 최적 AUC 0.804
- Out-of-location에서 AUC는 0.679 ± 0.154이며, 후자에서 기관지 및 폐 위치를 제외하면 낮지만 In-distribution과 비슷함. 이러한 결과를 보여주는 패턴에 대해서는 근거가 없음.
- 볼드체는 배경을 제외한 dataset, grey는 배경을 포함한 dataset임.
PatchCamelyon
※ 본 논문에서는 해당 결과에 대해 구두로만 서술하고, 정확한 fig나 table이 존재하지 않음.
- 15개 중 12개의 조합에서 0.428 ~ 0.612 사이의 매우 낮은 AUC
- α = 0.2, β = 0 일 때, AUC 0.672, 0.2, 0.2 일 때, AUC 0.802, 0.4, 0 일 때, AUC 0.758의 3가지 구성은 어느 정도 일반화되는 것으로 나타남.
위 두 실험은 proxy label에 대한 단순 classification임. 이러한 proxy label을 토대로 진행한 segmenatation은 다음과 같음.